


在当前互联网时代,平台作为一个
最简单的查询语句
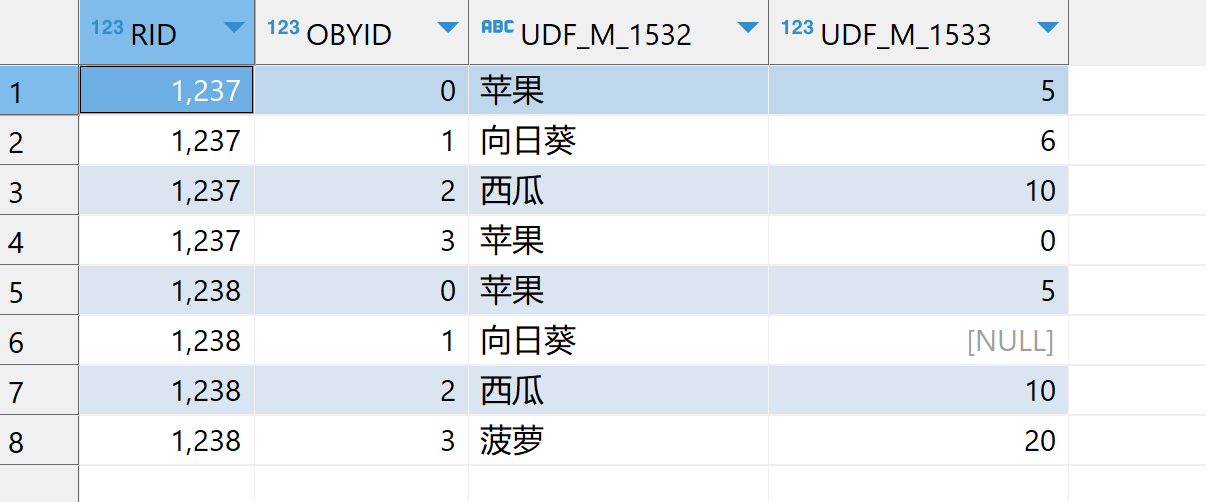
查询数据库表数据并展示所有列(字段) 查看截图
SELECT *
FROM WFXTFY.dbo.UDT_M_257查询数据表数据展示特定列(字段) 查看截图
SELECT UDF_M_1532 ,
UDF_M_1533
FROM WFXTFY.dbo.UDT_M_257
多表联合查询示例 JOIN
--左联结示例
SELECT * FROM 表1 LEFT JOIN 表2 ON 表1_id=表2_id;-- 使用JOIN语句进行三表左链接
SELECT 列名
FROM
表1 LEFT JOIN 表2 ON 表1.字段=表2.字段
LEFT JOIN 表3 ON 表2.字段=表3.字段;更详细教程请查看▼
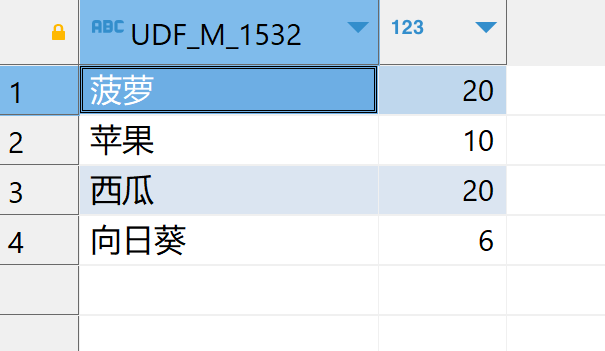
查询带统计列分组求和语句GROUP BY
SELECT UDF_M_1532,
SUM(UDF_M_1533)
FROM WFXTFY.dbo.UDT_M_257
GROUP BY UDF_M_1532常见问题
这是因为展示结果中含有统计(聚合)类型列,需要结合GROUP BY 才能正常使用
创建数据表 CREAT
CREATE TABLE bnqz_student (
id INT PRIMARY KEY ,
name VARCHAR(50) NOT NULL,
age int NOT NULL ,
sex VARCHAR(10)
)CREATE table A_插入行学习1(
id int,
name varchar(50),
age int,
sex varchar(50),
)-- 创建填报表
CREATE TABLE A1_填报表 (
ID INT , -- 假设ID是主键且自增
内容 VARCHAR(255) NOT NULL -- 假设内容字段是一个可变字符字段,最大长度为255
);
-- 创建插入表
CREATE TABLE A1_插入表 (
ID INT , -- 假设ID是主键且自增
内容 VARCHAR(255) NOT NULL -- 假设内容字段是一个可变字符字段,最大长度为255
);插入语句 INSERT
INSERT INTO语句用于向表格中插入新的行#插入数据
语法
- INSERT INTO 表名称VALUES(值1,值2,….)
- INSERT INTO table name (列1,列2,..)VALUES(值1,值2,)
期中方法1方式为全部字段,方法2可以是部分字段,对应字段类型要一致才不会出错
/*插入单行(条)数据#插入数据*/
INSERT INTO bnqz_student (id, name, age, sex)
VALUES (1001, '周木伦', 21, '男');
/*插入多行(条)数据*/
INSERT INTO bnqz_student (id, name, age, sex)
VALUES (1002, '刘得华', 25, '男'),
(1003, '小风', 29, '女'),
(1004, '赵木山', 51, '男');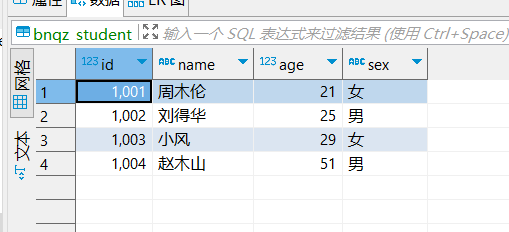
--插入部分字段内容
INSERT INTO a_插入行学习1 (id,NAME,AGE)
values (3,'李兴旺',28),
(4,'刘根生',25)INSERT INTO SELECT的用法
INSERT INTO 表名 (列1, 列2, 列3, …)
SELECT 列1, 列2, 列3, …
FROM 来源表
WHERE 条件;
INSERT INTO子句指定了要将数据插入的目标表和目标列。SELECT子句则定义了要从哪个表中选择数据,并指定了要插入到目标表的哪些列中。可以根据需要选择相应的列,这样就不必将所有列都插入到目标表中。
--插入查询到的结果到表中
INSERT INTO a_插入行学习1 (id,name,age,sex)
SELECT id,name,age,sex from A_插入行学习2
--插入查询到的结果到表中,
--查询结果为全部字段,用*表示
INSERT INTO a_插入行学习1 (id,name,age,sex)
SELECT * from A_插入行学习2
--从表2中提取年龄大于40的插入到表1
INSERT INTO A_插入行学习1 (ID,name,AGE,SEX)
SELECT * FROM A_插入行学习2
WHERE age >40--插入查询后的数据到某表
INSERT into A1_插入表
select id,内容 from A1_填报表
WHERE id<=2查询语句 SELECT
/*查询性别(sex)为男的平均年龄*/
SELECT AVG(age) AS "男性平均年龄"
FROM bnqz_student bs
WHERE sex = '男'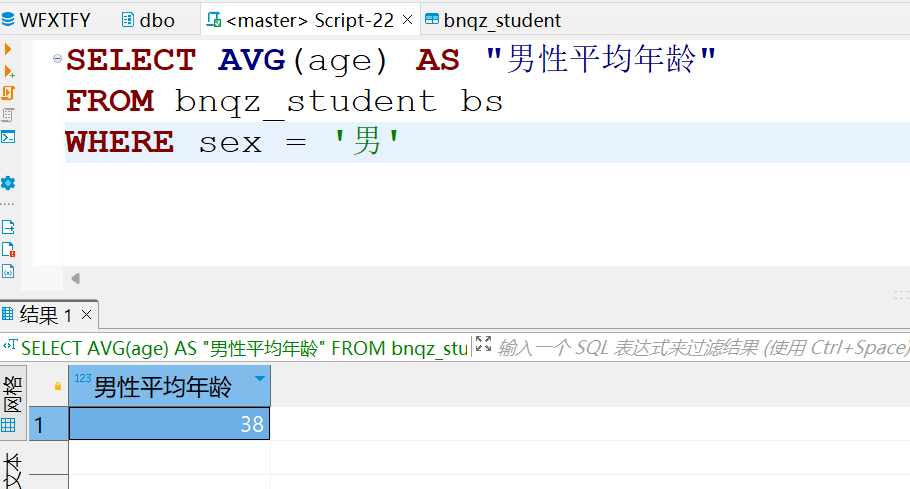
提取不重复值SQL Server
要从SQL Server中提取不重复的值,可以使用DISTINCT关键字。假设你有一个名为table_name的表,并且想要从名为column_name的列中提取不重复的值,可以使用以下SQL查询:
SELECTDISTINCT column_nameFROM table_name;这将返回column_name中的所有唯一值,每个值只会出现一次。
如果你想要对多列进行唯一性检查,可以在SELECT语句中包含多个列,例如:
SELECTDISTINCT column1, column2FROM table_name;这将返回column1和column2的所有唯一组合。如果表中有多行具有相同的值,那么这些值只会出现一次。
更新语句 UPDATE
/*更新姓名包含(形如)周字的数据*/
UPDATE bnqz_student
SET age = 10, sex = '保密'
WHERE name LIKE '%周%'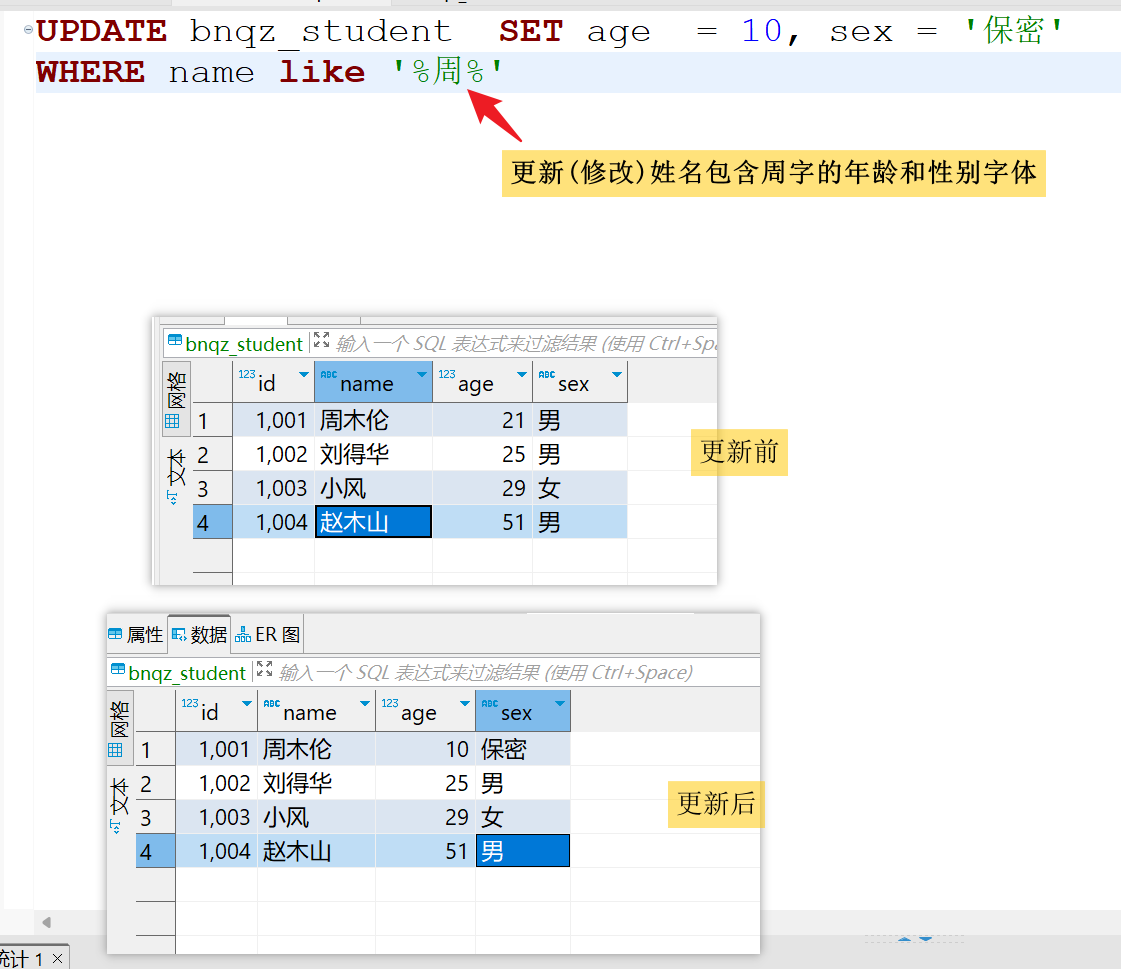
删除语句 DROP
DROP TABLE bnqz_student
/*bnqz_student为表名*/删除语句示例代码#删除数据
--创建表
CREATE TABLE 删除的应用 (
id INT ,
字段1 VARCHAR(50) )
/*插入多行(条)数据*/
INSERT
INTO
删除的应用 (id,
字段1)
VALUES (1002,'男'),
(1003,'女'),
(1004,'男');
--删除id等于1002的数据行
DELETE FROM
删除的应用
WHERE
id = 1002
--删除表中全部数据,且不可恢复
TRUNCATE
TABLE 删除的应用
--删除整个表
DROP TABLE 删除的应用更多删除语句请请查看下文

随机提取前N条数据
SELECT TOP(5) *
FROM tb_pub_city
ORDER BY NEWID();窗口函数
--窗口函数:按照性别分组后,再按随机排序排列
SELECT *, row_number() OVER (PARTITION BY sex ORDER BY newid()) AS 随机排序
FROM A_插入行学习2更多窗口函数学习

数据类型
文本
日期
数字
小数DECIMAL(P,D)
DECIMAL 数据类型用于在数据库中存储精确的数值,我们经常将该数据类型用于保留准确精确度的列,例如会计系统中的货币数据。
要定义数据类型为DECIMAL的列,请使用以下语法:
column_name DECIMAL(P,D);在上面的语法中:
P是表示有效数字数的精度。P范围为1〜65。D是表示小数点后的位数。D的范围是0~30。MySQL要求D小于或等于(<=)P。DECIMAL(P,D)表示列可以存储D位小数的P位数。十进制列的实际范围取决于精度和刻度。
系统级查询
获取所有的表名------
①select name from sysobjects where xtype='u';
②select name from sys.tables;
③select table_name from information_schema.tables;
获取所有字段名-----
①select name from syscolumns where id=object_id('表名');
②select column_name from information_schema.columns where table_name = '表名';
获取表的字段以及字段类型------
select table_name,column_name,data_type
from information_schema.columns
where table_name = '表名';
获取行数量-------
select rows from sysindexes where id = object_id('表名');原文链接
sql server获取所有表名、字段名、字段类型、表行数(转载) – PowerCoder – 博客园
https://www.cnblogs.com/OpenCoder/p/17771152.html






请登录后查看评论内容